Where motion becomes intelligence.
millions of high-fidelity synthetic frames
BEYOND 2D HUMAN POSE ESTIMATION


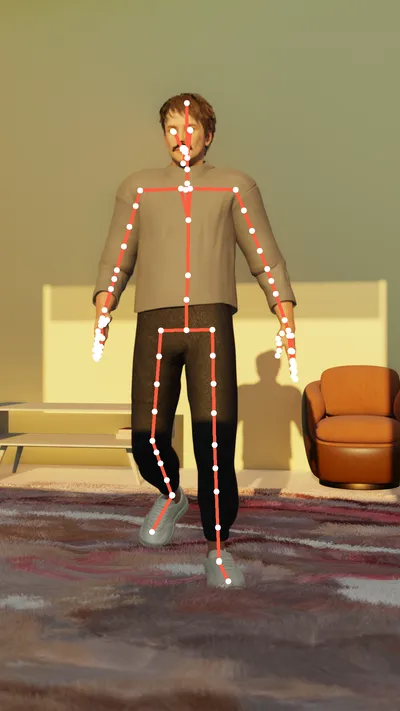
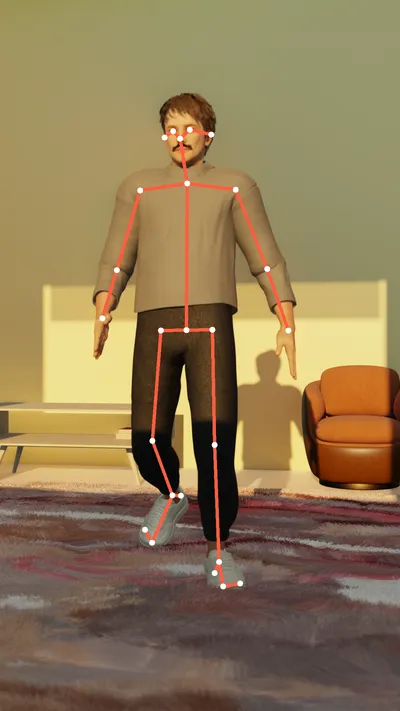


Generate body keypoints in different formats, both sparse (Coco, Mediapipe, Dense, SAM 3D, OpenPose) and dense.

Automatically generate perfect depth maps for 3D model training. Contains an occlusion-free character depth map.

Pixel-perfect segmentation for each main human body part.
Real Biomechanical Foundation
Why Computer Vision Needs Synthetic Data

Your model works perfectly in your test set, but fails in the real world. Your training data is limited by the specific people, lighting, and environments you recorded. Your model has never seen users with different body types, in cluttered living rooms, or in bad light conditions.
Our synthetic pipeline algorithmically generates the variability you can't capture manually. We create thousands of permutations for each movement:
- Motions: 700+ professional exercises and daily actions, featuring variations in speed, pace, and common postural errors.
- Users: Countless body shapes (BMI), skin tones, and clothing (t-shirts, hoodies, shorts).
- Environments: Bright gyms, dark bedrooms, cluttered living rooms, abstract backgrounds.
- Camera: Any angle, height, focal length, and distance.

Great AI models require great training data. But scaling a dataset manually is a financial nightmare, and typically yields only simple 2D data. Getting high-quality 3D motion data historically means paying for mocap studios, athletes, and post-processing specialists, without any promise of results.
Our pipeline eliminates this cost. And bypasses the traditional, error-prone 2D annotation process entirely. You get a production-ready 3D dataset today, for a fraction of the cost, saving you money and time.
Your algorithms are ready, but your data isn't. Relying on physical studios and manual annotation forces your engineering team to wait quarters—not sprints—to test a single hypothesis. This massive lag between idea and execution is the single biggest friction point in modern AI development.
We turn your data bottleneck into a data highway. You can have a production-ready, enterprise-scale dataset in a couple of days or weeks. Your engineers can spend that time on what truly matters: building, training, and deploying your model. Launch new features, new exercises, and new products in a fraction of the time.

Collecting real-world user video is a legal and ethical minefield. You have to navigate a complex web of privacy laws like GDPR and HIPAA. A single data breach could be catastrophic, costing millions in fines and destroying your users' trust.
Our data is 100% synthetic and anonymous. It contains no Personally Identifiable Information (PII)—no real faces, no real bodies. This completely eliminates all privacy and compliance risks. You can train and deploy your models with zero legal liability, ensuring your company and your users are fully protected.
Your model is only as good as its labels. When you use a human annotation team (or worse, crowdsourcing), you get inconsistencies, subjective errors, and bias. Moreover, when a limb is occluded or the lighting is poor, annotators are forced to guess the joint's location. As you scale your dataset, managing thousands of hours of manual annotation results in significant drift between labelers.
Our data is algorithmically precise. Every frame is labeled by our pipeline with pixel accuracy. The keypoint for the left elbow is in the exact same corresponding 3D space, every time. This provides a perfectly clean, objective, and consistent "ground truth" for your model, resulting in higher accuracy, faster training convergence, and more reliable performance.
Flexible Plans for Every Stage
Foundation
(12 month license)
150K FRAMES
What's Included:
- 30 exercise types from mocap library
- 5K synthetic frames per exercise
- Standard domain randomization
- Basic data modality (RGB, sparse keypoints)
Professional
(24 month license)
2M FRAMES
What's Included:
- 200 exercise types from mocap library
- 10K synthetic frames per exercise
- Standard domain randomization
- Full camera control
- Full data modality (RGB, depth, segmentation, keypoints and more)
- Technical integration support
Enterprise
(36 month license)
10M+ FRAMES
What's Included:
- Full mocap library (includes 700+ exercises and other movements)
- 20K synthetic frames per exercise
- Advanced domain randomization
- Multi-camera render with full control
- Full data modality
- Custom exercise additions
- Quarterly dataset updates
- Priority Integration & SLA
FREQUENTLY ASKED QUESTIONS
We use 3D software to generate massive human motion datasets containing thousands of video sequences with different body types, camera angles, lighting, environments, clothing, among others, while preserving the core biomechanical accuracy. This accuracy is made possible thanks to an extensive library of motions captured in Studio - professional-grade motion capture (mocap) data - which serves as our movement "ground truth".
Movements are ground in reality. The entire mocap library comes from 2+ years of investment in R&D to create one of the world's largest mocap exercise datasets, complemented with other hundreds of other human actions. We can optionally augment movements by generating random synthetic variations, originated from a real accurate performed motion, while still limited by human physical joint constraints.
We provide ready-to-train synthetic datasets. They contain RGB video sequences (frames), and each frame contains a pixel-perfect depth map, segmentation mask, sparse 2D/3D keypoints (in formats like COCO and MediaPipe) and dense keypoints. We also provide detailed information about character, like skin color, height, antropometric body measurements (skeleton length, skin perimeter, etc), among others. This level of granularity ensures your training data is balanced across all demographics, allowing you to create a truly unbiased model.
Our full library contains over 700 unique exercises, each featuring multiple variations in range of motion, overall execution speed, pace variation, and micro-stops, complemented by variations in non-essential limb positions for every action. For many of these exercises we collected 5-10 common postural errors, with additional variations.
Yes. We find it essential to capture the subtle nuances that can make a big impact on user condition, health or performance. Our library includes many of the most common postural errors for a wide range of exercises, which allows you to train your AI to not only recognize an exercise but to accurately correct a user's form (e.g., "arched back" in a squat, "flared elbows" in a push-up)
No. Our library also covers a wide range of other human actions (non-exercises), including dances, daily behaviours, locomotive and postural transitions, daily routines and activities, common chores, personal care, and others.
Yes. Models often fail on "edge cases," so we intentionally generate them. Our datasets include randomized variations in lighting (e.g., dark rooms, strong shadows), camera angles / position, and clothing fit (e.g., baggy shirts that hide body shape) to ensure your AI becomes robust against real-world unpredictability.
Unlike human annotators who have to guess where a hidden hand or foot is, we have access to the accurate position of every body part. This allows us to provide accurate keypoints even when a limb is fully occluded by the body or objects, giving your model "superhuman" ground truth to learn from.
Our data is for AI/ML teams building applications that rely on precise human motion understanding. Our primary focus areas are in Fitness Technology (for rep counting, form correction, action recognition), MSK Digital Health (for remote physiotherapy, ergonomics), and R&D/Innovation Labs.
We license our datasets on an annual basis (typically 12, 24, or 36 months). This license allows your team to use the data for all internal R&D, model training, and for deployment in your final commercial application. The data itself cannot be resold or redistributed.
Because our data is 100% synthetic, it contains no "Personally Identifiable Information" (PII). There are no real faces, bodies, or personal data. This completely bypasses all compliance issues related to GDPR, HIPAA, and other privacy regulations, which is a major advantage over collecting real-world user data.
"Foundation" and "Professional" plans provide access to a subset of our exercise library. For the "Enterprise" plan, we offer access to the full library as well as the option to commission custom movements additions.
No. The synthetic data we generate is deterministic, procedural and grounded in physics. Gen-AI models tend to 'hallucinate' movement based on statistical patterns (even with conditional prompting) and we could never match the level of biomechanical accuracy of real motion capture data. Equally as important, because we build the 3D scene, we provide perfect "ground truth" labels (segmentation, depth, keypoints), whereas a pixel—something generative AI can only guess at.
Contact us and a member of our team will get in touch to understand your needs and provide a relevant data slice for your evaluation.
THE FUEL FOR YOUR INNOVATION
Fitness Technology
Power your fitness app with precise motion tracking. Perfect for accurate rep counting, form correction, and providing users with actionable real-time feedback.
MSK Digital Health
Develop next-generation digital health solutions for musculoskeletal (MSK) care, remote physiotherapy, and ergonomic analysis with clinically-validated data.
Innovation Labs
Fuel your R&D for any application that involves human motion. From AR/VR experiences to robotics, our data provides the ground truth you need to innovate.